Språkmodellers inntog fører til økning i klager
I tillegg til at vi mottar stadig flere klager fra enkeltpersoner, er klagene også vanskeligere og mer tidkrevende å behandle.
Som enkeltperson kan du klage til Datatilsynet dersom du har opplevd noe du mener er et brudd på personvernregelverket.
De siste årene har Datatilsynet opplevd en markant økning i antall klager vi mottar, og veksten tok skikkelig fart i 2025. Fra 2024 til 2025 mer enn doblet antallet seg, fra 902 til 1848 klager. Basert på antallet klager så langt i år, er det mye som tyder på at denne trenden fortsetter.
Denne økningen sammenfaller med en annen trend: Offentlig sektor i hele landet opplever en dramatisk økning i saker fra enkeltpersoner som er utformet ved hjelp av generativ kunstig intelligens (KI), mer spesifikt språkmodeller som for eksempel ChatGPT eller Gemini.
I Datatilsynet har vi analysert klagene som virker å være generert ved hjelp av KI. Ikke bare får vi flere klager, men klagene som er skrevet ved hjelp av KI er ofte vanskeligere og mer tidkrevende å behandle på vår kant.
Hvor mange klager får vi som virker å være KI-generert?
For å finne ut i hvor stor grad KI blir brukt i klager, har vi gått igjennom klagene fra noen utvalgte måneder i løpet av det siste året.
Vi delte klagene i tre kategorier:
- Uten KI – Klager som ikke ser ut til å ha vært laget ved hjelp av språkmodeller
- Hybrid – Klager som ser ut til å være delvis skrevet selv og delvis skrevet ved hjelp av språkmodeller
- Med KI – Klager som gjennomgående hadde et karakteristisk preg av å være skrevet av enspråkmodell
Se kriteriene vi brukte for å vurdere hvorvidt en klage er KI-generert eller ikke nederst i denne teksten.
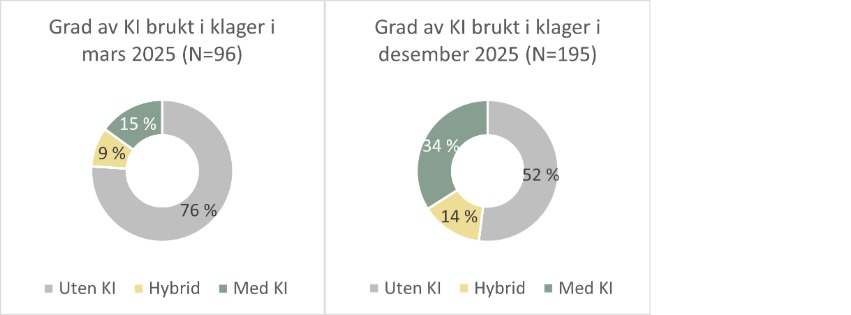
Ett av funnene våre var at andelen klager vi mottok, som hadde et karakteristisk KI-preg gjennom hele teksten, økte fra 15 prosent i mars 2025 til 34 prosent i desember 2025 (se figur over). Dette betyr at ved årets slutt kan så mye som én av tre klager ha blitt utformet med hjelp av KI.
For å få et innblikk i når denne trenden startet, sammenlignet vi også klagene vi mottok i mai 2024 med samme måned i 2025. I mai 2024 var det kun 2 prosent av klagene som hadde et karakteristisk preg av å være utarbeidet ved hjelp av KI, mot 23 prosent i 2025. Siden den tid har altså andelen vokst ytterligere
Hvordan påvirker KI saksbehandlingen?
Mange av de KI-genererte klagene mangler en beskrivelse av hva som faktisk har skjedd, og dokumentasjon på kontakt med virksomheten eller personen som de ønsker å klage på. Dette gjelder spesielt de tilfellene der klageren i liten grad redigerer tekstforslaget fra språkmodellen før de sender klagen til oss.
Vi ser også ofte at slike klager inneholder overflødig og generell informasjon, og kan dermed bli svært omfattende. Klagere presenterer gjerne en rekke klagemål og henviser til bestemmelser i lovverket som angivelig har blitt brutt, gjerne også bestemmelser som ikke gir klageadgang, eller ikke eksisterer. Resultatet ser imponerende ut, men mangler ofte vesentlig eller korrekt informasjon.
På mottakersiden sitter en saksbehandler som må forholde seg til store mengder tekst, et mangelfullt faktagrunnlag, og hvor det er uklart hva klageren egentlig ønsker å klage på. For å kunne behandle saken må saksbehandleren avgrense klagen og etterspørre nødvendig informasjon fra klager, et merarbeid som gir lengre saksbehandlingstid.
Klage til Datatilsynet? Bare fakta, takk!
Enten du skriver klagen ved hjelp av KI eller helt for egen maskin: Her er noen tips til deg som skal sende inn en klage som kan bidra til mest mulig effektiv og god behandling.
Sørg for at klagen inneholder:
1. En kort forklaring om hva den du klager på har gjort med dine personopplysninger som du mener er ulovlig.
For eksempel: «Min arbeidsgiver har satt opp kameraer på min arbeidsplass som peker mot min arbeidsstasjon, lageret og pauserommet. Sjefen min bruker opptakene til å kontrollere eller sjekke om jeg gjør jobben min riktig. Sjefen sitter hjemme og følger med på hva jeg gjør og ringer for å kjefte når hen mener jeg gjør noe galt.»
2. Dokumentasjon på hvilken kontakt det har vært med virksomheten eller personen du klager på. Om dere ikke har vært i kontakt, forklar hvorfor.
For eksempel: «Jeg har sendt en epost til sjefen min og sagt ifra om at dette ikke er ok, og fikk beskjed om at jeg bare måtte finne meg i det eller slutte. Se vedlagt e-postutveksling».
Det er ikke nødvendig å vise til hvilke bestemmelser i regelverket som kan ha blitt brutt, eller hva Datatilsynet skal gjøre for å løse saken. Dette er oppgaver som Datatilsynet selv vil kunne identifisere basert på faktagrunnlaget.
Hva så vi på for å vurdere om klagen var utformet ved hjelp av KI?
- Format: Hyppig bruk av fet skrift, punktlister, lange tankestreker m.m.
- Språk og tone: Uvanlig korrekt og polert språk, henvisninger til lovhjemler, krav m.m.
- Struktur: Rapportformat, lange avsnitt, generelle argumenter m.m.
- Innhold: Mangler detaljer som dato, navn, hendelser og steder, kommunikasjon m.m.
Høgdepunkt frå året som gjekk
Kvar vår sender vi årsrapporten vår til departementet og Stortinget. Sjølve behandlinga av årsrapporten skjer først til hausten, men for oss i Datatilsynet er dette eit godt høve til å stoppe opp og reflektere over kva for retning personvernet tek i Noreg....
Personvern er beredskap i en urolig verden
Samfunnssikkerhet handler ikke lenger bare om soldater, forsyningslinjer og fysisk infrastruktur, men også om data, teknologi og kontroll over informasjon. I en verden preget uro, er personvern en viktig del av vår nasjonale beredskap.
Digital svindel: Ikke gjør personvernet til syndebukk
GDPR er ikke hinderet for å bekjempe svindel gjennom datadeling. Når personvernreglene får skylden, mister vi raskt blikket for de reelle utfordringene og løsningene.
Kameraovervåking av hus og hytte. Noen enkle råd fra Datatilsynet
Kameraovervåking er et tema mange er opptatt av – ikke minst nå på høsten når mange vil ut i høstfjellet, men oppdager kamera i hyttefeltet. Vi får jevnlig mange henvendelser fra personer som er usikre på reglene for egen bruk av kamera eller som opplever å bli...
Chatbot på rømmen
VG har lansert chatboten heiVG og det har allerede blitt oppdaget at den gir uriktige opplysninger om levende personer. Hvem har ansvaret når chatboten gjør feil?
Bedre etter snar enn føre var, Høyre og Venstre?
Det som overrasker oss mest, er at Høyre og Venstre, som er de eneste partiene som støtter Arbeiderpartiregjeringens lovforslag, i innstillingen snur alle personvernprinsipper og -prosedyrer på hodet. De vil gjennomføre lovarbeidet først, og heller forholde seg til personvernkonsekvensene etterpå.
Digitaliseringsparadokset
I prosessen med å bli verdens mest digitaliserte land risikerer vi å få verdens mest overvåkede innbyggere. Innlegget er skrevet av direktør Line Coll og juridisk spesialrådgiver Jan Henrik Nielsen.
Barn har en grunnlovsfestet rett til personvern
Datatilsynet og Utdanningsforbundet håper Stortingets politikere ikke lar seg avlede av lettvint retorikk, og fordreining av hva dette egentlig handler om: opprettelsen av store, inngripende individregistre som rent faktisk utfordrer både det grunnlovfestede vernet av barns personlige integritet og personvernet som demokratisk samfunnsverdi.
Overvåkning til barnets beste?
Forslaget om et nasjonalt individregister for barn dreier seg ikke om små, tilforlatelige endringer av barnehageloven, opplæringsloven og privatskoleloven. Det handler om opprettelsen av store, inngripende individdataregistre som både utfordrer det grunnlovfestede vernet av barns personlige integritet og personvernet som demokratisk samfunnsverdi, skriver Camilla Nervik og Geir Røsvoll.
Seks sentrale spørsmål om kunstig intelligens (Og svarene fra sandkassen)
Siden oppstarten i 2021 har Datatilsynets regulatoriske sandkasse hjulpet enkeltaktører med å følge regelverket og utvikle KI-løsninger med godt personvern. Fremover vil vi ha et bredere fokus på innovasjon og digitalisering – både med og uten kunstig intelligens. Men...